Pyppeteer 优势
- 不用像Selenium一样配置浏览器环境
- 可以直接在页面上进行爬取,爬取的不是页面源码而是已经加载完毕的,显示在浏览器上的页面
- 可以绕过加密系统
Pyppeteer 加载的 text() 是加载完成后的 HTML 页面,所有数据调出,Pyppeteer 获取的是加载完成的网页数据。
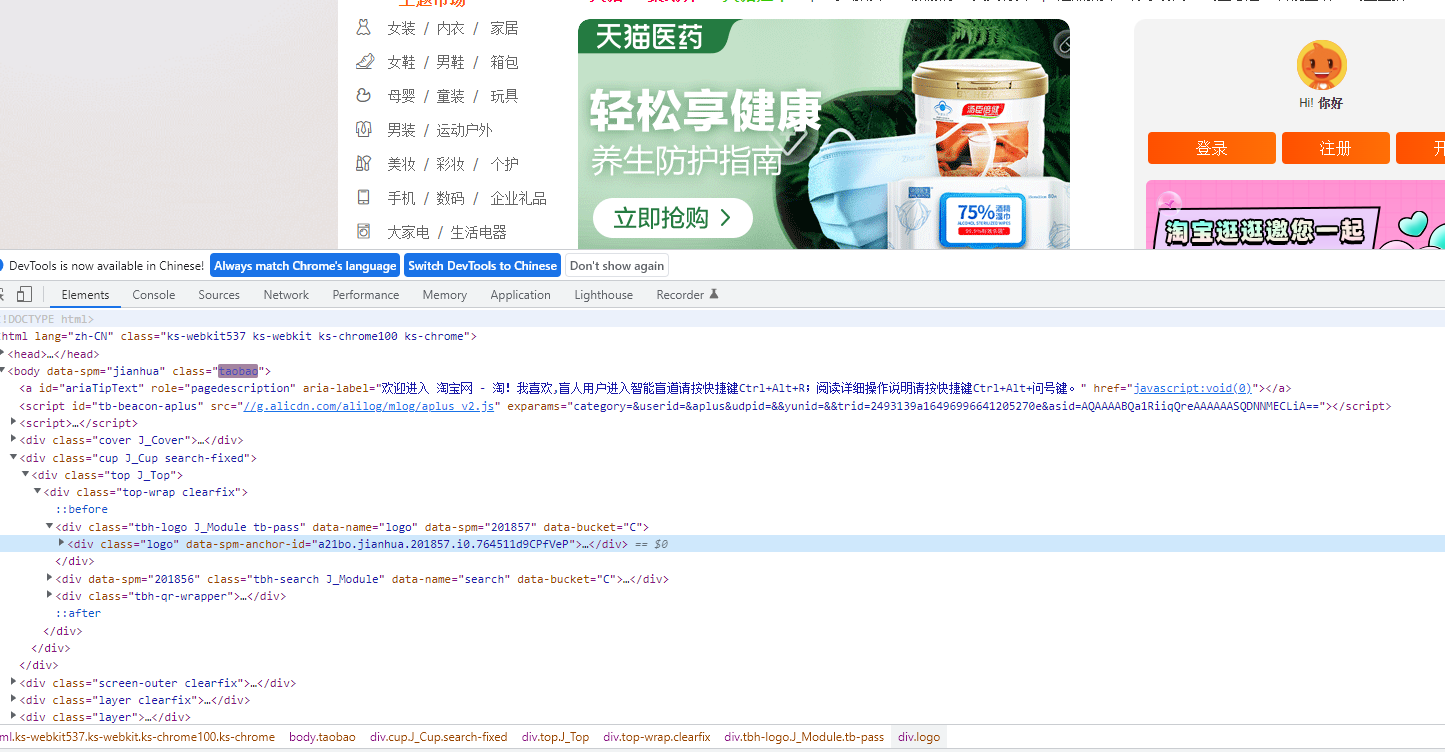
Request 查看的是网页源码,内部可能有 JS 的调用或者 Ajax 接口导致代码不全。
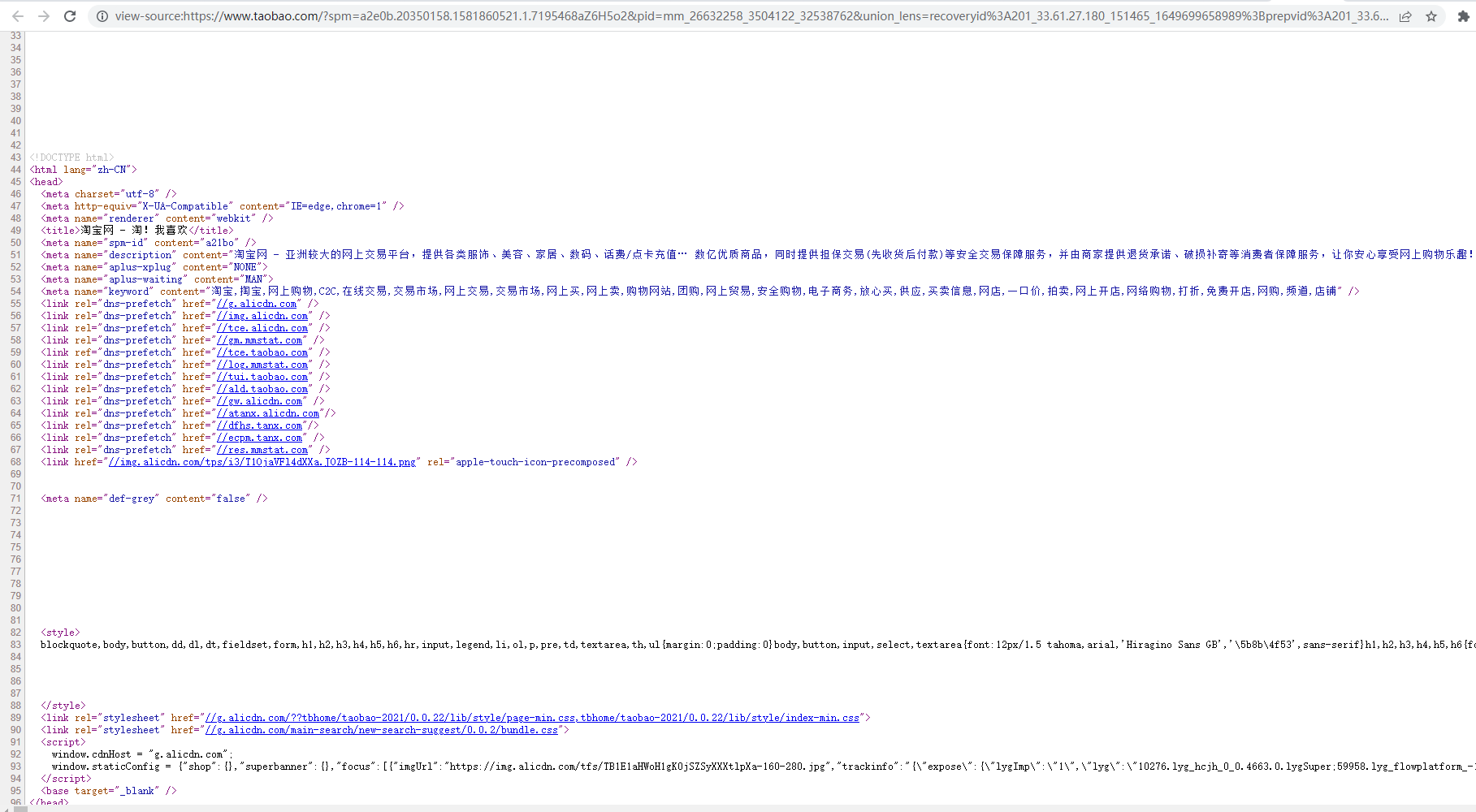
爬取京东数据
安装:pip install pyppeteer
爬取思路:
- 观察京东页面
- 在搜索框中输入 “耳机”,点击搜索
- 抓取前三页的数据
- 实现翻页
代码设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
import asyncio # 协程
from pyppeteer import launch
from pyppeteer_stealth import stealth
width, height = 1366, 768
async def main():
"""主函数"""
'''一、打开浏览器
headless=True——无头模式,无法看见浏览器爬取过程
headless=False——可视化,可以在页面中看见浏览器
'''
browser = await launch(headless=False)
'''二、新建标签页'''
page = await browser.newPage()
'''三、消除指纹
浏览器指纹:
你的浏览器具有非常独特的指纹,那么当你第一次访问某网站的时候,网站会在服务器端记录下你的浏览器指纹,并且会记录你在该网站的行为;
下次你再去访问的时候,网站服务器再次读取浏览器指纹,然后跟之前存储的指纹进行比对,就知道你是否曾经来过,并且知道你上次访问期间干了些什么。
---
浏览器指纹威胁:
浏览器指纹”无需在客户端保存任何信息,不会被用户发觉,用户也无法清除(换句话说:你甚至无法判断你访问的网站到底有没有收集浏览器指纹)会被追踪
'''
await stealth(page)
'''四、设置窗口大小'''
await page.setViewport({'width': width, 'height': height})
'''五、前往目标网页'''
await page.goto('https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_c40b68367c9e42489ad40ec69c3a693a')
'''六、暂停两秒,等待页面完全加载'''
await asyncio.sleep(2)
'''七、定位搜索框,搜索框id=key
参数一:#name 定位 class=name 的元素;.name 定位 id=name 的元素
参数二:**{‘timeout’: 9000}**字典,定位目标元素等待的时间9s
'''
await page.waitForSelector('#key', {'timeout': 9000})
'''八、定位完元素后,在元素中填入字符'''
await page.type('#key', '耳机')
await asyncio.sleep(1)
'''九、点击事件'''
await page.click('.button')
await asyncio.sleep(2)
# 翻页
for num in range(3):
# 页面滑动事件,滚动浏览器滚动条至底部, 滑动多少调改变数字便可
await page.evaluate('window.scrollBy(100, document.body.scrollHeight)')
await asyncio.sleep(1)
# 滑动两次提取更多数据
await page.evaluate('window.scrollBy(200, document.body.scrollHeight)')
# //*[@id="J_goodsList"]/ul/li[1] 商品Xpath
li_list = await page.xpath('//*[@id="J_goodsList"]/ul/li') # 获取数据,获取到的是Json数据
print(len(li_list))
for i in li_list:
# ./div/div[4]/a/em
a = await i.xpath('./div/div[4]/a/em')
print(a)
# 获取数据
title = await (await a[0].getProperty("textContent")).jsonValue()
print(title)
# 下一页按钮class是pn-next
await asyncio.sleep(1)
await page.click('.pn-next')
print('*'*20)
await asyncio.sleep(100)
# 执行异步
asyncio.get_event_loop().run_until_complete(main())
代码优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
# -*- coding:utf-8 -*-
"""
@Author : haauleon
@Contact : 753494552@qq.com
@File : pyppeteer_jd_product.py
@Date : 2022-05-13 10:56:00
@Function:
1. 爬取京东商品标题
2. 注意:
- 此脚本使用 pyppeteer 异步框架实现
- 此脚本在 macOs 系统下使用 python 控制台运行成功, win 系统未调试过
"""
import asyncio # 协程
from pyppeteer import launch
from pyppeteer_stealth import stealth
class JDProduct:
"""京东商品"""
def __init__(self):
self.width, self.height = 1366, 768
async def _init(self):
"""初始化浏览器"""
self.browser = await launch(
{
'headless': True, # 浏览器是否启用无头模式
'args': ['--disable-extensions',
'--hide-scrollbars',
'--disable-bundled-ppapi-flash',
'--mute-audio',
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-gpu',
'--disable-infobars',
],
'dumpio': True, # 不添加会卡顿,
'autoClose': True # 在自动关闭浏览器的时候删除tmp文件
}
)
# 在浏览器创建新标签页
self.page = await self.browser.newPage()
# 消除指纹
await stealth(self.page)
# 设置浏览器头部
await self.page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ')
# 设置窗口大小(如果设置了无头模式就屏蔽掉这里)
await self.page.setViewport({'width': self.width, 'height': self.height})
async def _insert_js(self):
"""注入js"""
# 本页刷新后值不变
await self.page.evaluate(
'''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
async def goto_page(self, page_url):
"""前往目标网页"""
await self.page.goto(page_url, timeout=0)
# 等待页面完全加载
await asyncio.sleep(2)
async def ele_click(self, selector):
"""点击操作"""
await self.page.waitForSelector(selector, {'timeout': 9000})
await self.page.click(selector)
await asyncio.sleep(2)
async def run_to_handle_product(self):
"""爬取京东商品图片"""
await self.page.goto('https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign'
'=t_288551095_baidupinzhuan&utm_term'
'=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_c40b68367c9e42489ad40ec69c3a693a')
# 等待页面完全加载
await asyncio.sleep(2)
# 定位搜索框,搜索框id=key
await self.page.waitForSelector('#key', {'timeout': 9000})
# 搜索框填写
await self.page.type('#key', '耳机')
await asyncio.sleep(1) # 等待1s
# 点击 按钮的class为button
await self.ele_click('.button')
# 翻页
for num in range(3):
# 滚动浏览器滚动条至底部
await self.page.evaluate('window.scrollBy(100, document.body.scrollHeight)')
await asyncio.sleep(1)
# 滑动两次提取更多数据
await self.page.evaluate('window.scrollBy(200, document.body.scrollHeight)')
# //*[@id="J_goodsList"]/ul/li[1] 商品Xpath
li_list = await self.page.xpath('//*[@id="J_goodsList"]/ul/li')
print(len(li_list))
for i in li_list:
# ./div/div[4]/a/em
a = await i.xpath('./div/div[4]/a/em')
# print(a)
# 获取数据
title = await (await a[0].getProperty("textContent")).jsonValue()
print(title)
# 下一页按钮class是pn-next
await asyncio.sleep(1)
await self.ele_click('#J_bottomPage > span.p-num > a.pn-next')
print('*' * 50)
await asyncio.sleep(100)
async def main(self):
"""主函数"""
await self._init()
await self._insert_js()
await self.run_to_handle_product()
await self.page.close() # 关闭标签页
await self.browser.close() # 关闭浏览器
if __name__ == '__main__':
jd = JDProduct()
loop = asyncio.get_event_loop() # 创建一个事件循环对象loop
task = asyncio.ensure_future(jd.main()) # 执行异步
loop.run_until_complete(task) # 完成事件循环,直到最后一个任务结束